
注意
点击此处下载完整的示例代码,或通过 Binder 在浏览器中运行此示例
模型解释¶
以下示例展示了如何使用 auto-sklearn 拟合一个简单的分类模型,并利用 scikit-learn 的 inspection 模块来理解哪些因素影响了预测结果。
import sklearn.datasets
from sklearn.inspection import plot_partial_dependence, permutation_importance
import matplotlib.pyplot as plt
import autosklearn.classification
加载数据并构建模型¶
我们首先从 OpenML 加载“跑还是走”数据集,并在其上训练一个 auto-sklearn 模型。对于此数据集,目标是根据手机收集的加速度计和陀螺仪数据来预测一个人是在跑还是在走。更多信息请参阅此处。
dataset = sklearn.datasets.fetch_openml(data_id=40922)
# Note: To speed up the example, we subsample the dataset
dataset.data = dataset.data.sample(n=5000, random_state=1, axis="index")
dataset.target = dataset.target[dataset.data.index]
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
dataset.data, dataset.target, test_size=0.3, random_state=1
)
automl = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=120,
per_run_time_limit=30,
tmp_folder="/tmp/autosklearn_inspect_predictions_example_tmp",
)
automl.fit(X_train, y_train, dataset_name="Run_or_walk_information")
s = automl.score(X_train, y_train)
print(f"Train score {s}")
s = automl.score(X_test, y_test)
print(f"Test score {s}")
/home/runner/work/auto-sklearn/auto-sklearn/autosklearn/data/target_validator.py:187: UserWarning: Fitting transformer with a pandas series which has the dtype category. Inverse transform may not be able preserve dtype when converting to np.ndarray
warnings.warn(
Train score 0.9948571428571429
Test score 0.9813333333333333
计算置换重要性 - 第 1 部分¶
由于 auto-sklearn 实现了 scikit-learn 接口,因此可以与 scikit-learn 的 inspection 模块一起使用。所以,现在我们首先来看一下置换重要性,它定义了当给定特征被随机置换时,模型分数降低的程度。因此,分数越高,模型的预测结果就越依赖于此特征。
注意:解释这些数字时存在一些陷阱,可以在scikit-learn 文档中找到。
r = permutation_importance(automl, X_test, y_test, n_repeats=10, random_state=0)
sort_idx = r.importances_mean.argsort()[::-1]
plt.boxplot(
r.importances[sort_idx].T, labels=[dataset.feature_names[i] for i in sort_idx]
)
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
for i in sort_idx[::-1]:
print(
f"{dataset.feature_names[i]:10s}: {r.importances_mean[i]:.3f} +/- "
f"{r.importances_std[i]:.3f}"
)
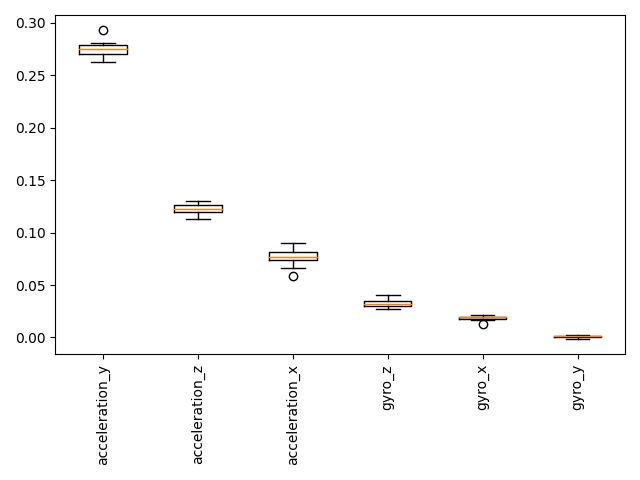
gyro_y : 0.001 +/- 0.001
gyro_x : 0.018 +/- 0.002
gyro_z : 0.033 +/- 0.004
acceleration_x: 0.076 +/- 0.009
acceleration_z: 0.123 +/- 0.005
acceleration_y: 0.275 +/- 0.008
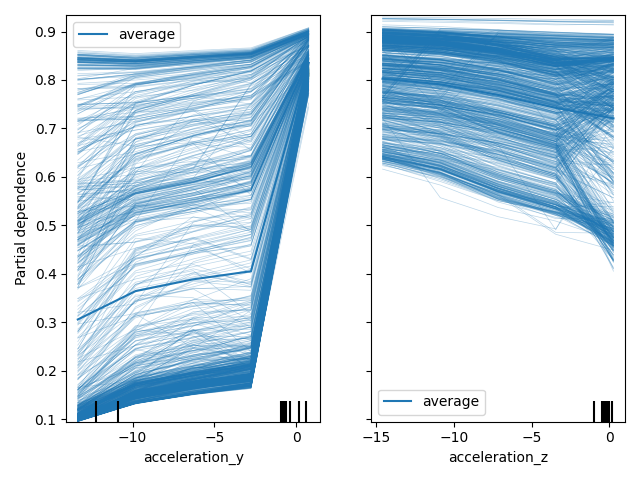
创建部分依赖性 (PD) 和个体条件期望 (ICE) 图 - 第 2 部分¶
ICE 图描述了特征值与每个样本的响应值之间的关系——它展示了当一个特征的值改变时,响应值如何变化。
PD 图描述了特征值与响应值之间的关系,即相对于一个或多个输入特征的预期响应值。由于我们使用的是分类数据集,这对应于预测的类别概率。
由于 acceleration_y 和 acceleration_z 根据置换依赖性对响应值的影响最大,我们将首先查看它们并生成一个结合了 ICE(细线)和 PD(粗线)的图。
features = [1, 2]
plot_partial_dependence(
automl,
dataset.data,
features=features,
grid_resolution=5,
kind="both",
feature_names=dataset.feature_names,
)
plt.tight_layout()
plt.show()
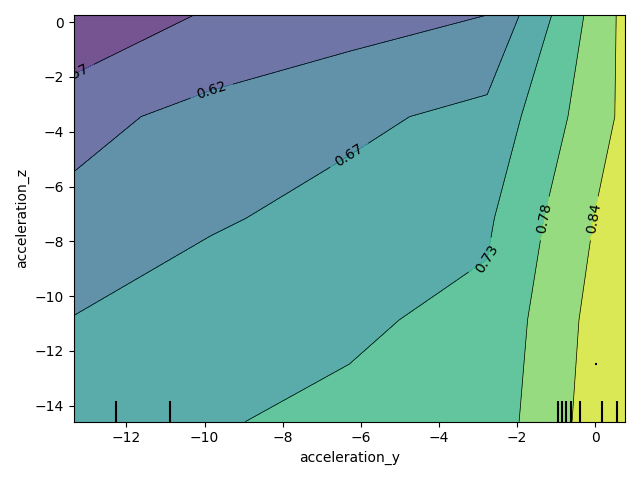
为多个特征创建部分依赖性 (PDP) 图 - 第 3 部分¶
PD 图也可以为两个特征生成,从而可以检查这些特征之间的交互作用。同样,我们将查看 acceleration_y 和 acceleration_z。
features = [[1, 2]]
plot_partial_dependence(
automl,
dataset.data,
features=features,
grid_resolution=5,
feature_names=dataset.feature_names,
)
plt.tight_layout()
plt.show()
脚本总运行时间: ( 4 分 9.332 秒)